DDL
CREATE:创建数据库和表对象
DROP:删除数据库和表对象
ALTER:修改数据库和表对象
DML
INSERT UPDATE DELETE SELECT
DCL
COMMIT:确认对数据的修改
ROLLBACK:回滚对数据的修改
GRANT:赋予用户权限
REVOKE:取消用户操作的权限
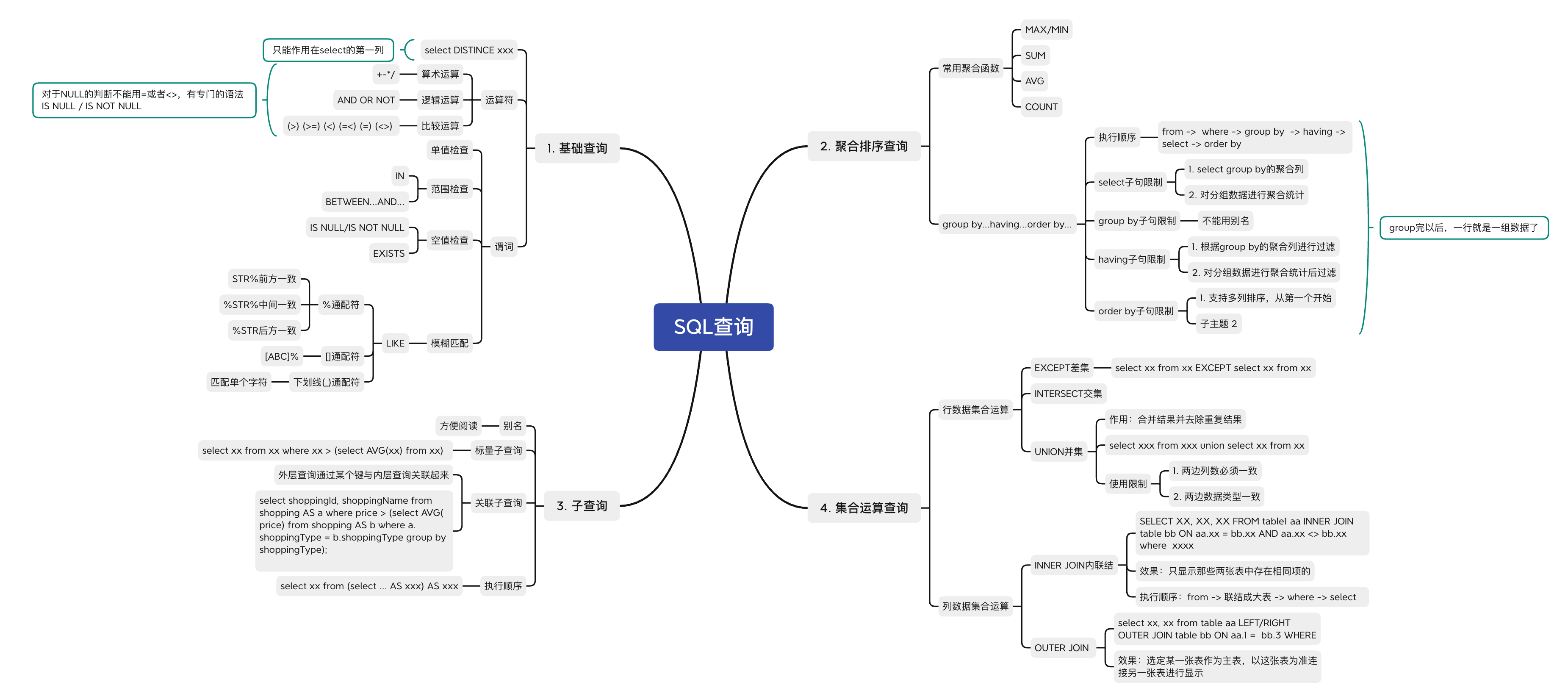
一. sql基本规则
分号结尾;
关键字不区分大小写
字符串和日期需要使用单引号''括起来
单词之间使用空格或换行符分隔
1.1 数据库创建
1
CREATE DATABASE <数据库名称>;
1.2 数据库表创建
CREATE TABLE <表名> (
<列名> <数据类型> <该列所需的约束>,
<列名> <数据类型> <该列所需的约束>,
<列名> <数据类型> <该列所需的约束>,
...
<该表的约束1>, <该表的约束2> ...
);
命名规则:数据库名,表名,列名只支持字母,数字和下划线_,且必须以字母开头
1.3 数据库表删除(无法恢复)
1
DROP TABLE <表名>;
1. 4 修改表结构(无法恢复)
1
2
ALERT TABLE <表名> ADD COLUMN <列名>;//添加列
ALERT TABLE <表名> DROP COLUMN <列名>;//删除列
1.5 数据库表的数据类型
INTEGER
整数,不能存小数(多少个字节?
CHAR
定长字符串,RDBMS不同,单位也不同,有的是字节作为单位,有的是字符作为单位。
字符最终都是根据一定的编码规则转换成字节数组进行存储,一般一个字符转换后的字节为1-3个
VARCHAR
可变长字符串,定长字符串在字符串不够的时候会空格补充,而可变长字符,当长度不够的时候也不会自动补充。
DATE
二. 数据库查询
2.1 基本sql
1
select ... from ...
2.2 子句
以select 和 from 作为起始的短语,字句是sql语句的总要组成部分
2.3 别名
给查询的列以别名
1
2
3
4
5
6
7
8
9
10
select jod_id AS id,
jod_name AS name,
jod_tanka AS tanka
FROM job;
select jod_id AS id,
jod_name AS "名字",
jod_tanka AS "坦克"
FROM job;
/*别名可以使用汉字,但是汉字需要用双引号括起来。*/
2.4 常数查询
1
2
3
select "商品" AS "名称",
"2020-02-02" AS "日期"
from <table_name>
2.5 DISTINCT去重
在select字句中使用DISTINCT可以删除重复行,且注意DISTINCT只能作用在第一个列名前面。
1
select DISTINCT <列名> from <表名>;
2.6 where选择
SQL中子句的顺序是固定的,不能随意更改,SELECT - FROM - WHERE
1
select <列名> from <表名> where <条件表达式>;
2.7 注释
”–“单行注释
/**/多行注释
2.8 算术运算符
四则运算主要运算符 + - * /
注意的是所有的算术运算,和NULL做运算的结果都是NULL
from子句不是必不可少的,如果只是通过sql进行运算,不要from子句也是可以的
2.9 比较运算符
= (等于) <> (不等于)
>= (大于等于) <=(小于等于)
>(大于)<(小于)
运算比较符号的两边可以是字符,数字和日期等几乎所有数据。
注意对字符的比较和对数字的比较是不用的, 对字符的比较是按照字典顺序进行比较的。
NULL的比较运算
对列做选择的过滤的时候,不管是使用where xx=NULL还是通过比较运算符进行查询都无法查到对应的记录,SQL提供了专门的语法来判断,IS NULL, where IS NULL; 或者 IS NOT NULL
2.10 逻辑运算符
NOT AND OR
不能单独使用,必须在其他的查询子句前面。使用逻辑运算符运算出来的结果叫真值(true, false)
NULL的逻辑运算
当一列中存在NULL的时候,通过 WHERE xx = xx 或者 WHERE NOT xx =xx都不能查出包含NULL的数据,这是因为在SQL中,真值除了true和false,还有一种状态unknown。一般的真值运算只有true/false称为二值运算,而sql的中的值运算有三个值, 称为三值运算。
三. 聚合排序
3.1 常用聚合函数
SUM AVG MAX MIN COUNT,还有很多其他的聚集函数,聚合函数主要用在行数据的聚合运算,因此可以放在select 子句中, 还有就是对组数据进行聚合,所以可以在
COUNT
计算NULL以外的数据行数,当count函数指定列名的时候,统计的是非空行数的结果,指定列中包含NULL的将不会保留进统计结果里。count(*)的便会一起统计NULL结果,同时入参为星号*的只有这一个。
SELECT COUNT(*) COUNT(XXX) FROM TABLE_NAME;
SUM
上面说了加减乘除的四则运算和NULL做运算时结果都是NULL,但是聚合函数SUM会把NULL排除在外,所以包含NULL的列计算结果不会是NULL。
SELECT SUM(XXX) AS XXX_SUM SUM(III) AS III_SUM FROM TABLE_NAME;
AVG
注意AVG也是和sum一样,会在计算之前先把NULL剔除在外。但是也可以将NULL作为0进行计算
SELECT AVG(XXX) AS XXX_AVG FROM TABLE_NAME;
MAX/MIN
最大值最小值计算的MAX/MIN和上面的SUM/AVG稍微不同,SUM/AVG只对数值结果有效,MIN/MAX几乎对所有的数据类型都生效。特别的对于日期和字符串,SUM/AVG是没用的,MIN/MAX是可以的。
去除重复行的数据,例如一张表中的一列有8行数据, 衣服2行,办公用品3行,厨房用品1行,想统计这一行的衣服种类,这个时候可以通过DISTINCT进行去重后再统计。
1
SELECT COUNT(DISTINCT <列名>) FROM table_name;
3.2 group by分组
分组关键字是group by
where子句与group by字句的书写顺序:select -> from -> where -> group by.
where子句与group by子句的执行顺序:from -> where -> group by -> select
执行顺序理解:
- (from->where)先从表过滤符合where条件的行数据
- (group by)对过滤出来的行数据进行分组成组数据
- (select)对组数据进行select子句查询
group by对NULL数据的处理
如果聚合键中存在NULL数据, 会单独为NULL数据作为一组。
3.2.1 group by 子句使用常见错误
select 子句中写了多余的列
使用group by子句分组后的数据,只能有两种用途:一个是select group by的聚合列;另一个是对分组后的数据使用聚合函数进行统计。也就是select 子句中只能存在三种元素:
- group by聚合列
- 聚合函数
- 还有常数
不能select聚合建以外的别的列的原因是因为进行group by以后,一行就是一组数据了,这时如果要select聚合键以外的列的话,聚合键和这个列的关系有可能不是一一对应的,无法表示。
group by子句中使用别名
select afa as xxx from table group by xxx;这个时候group by的xxx会报错,因为执行顺序是先执行group by子句进行分组了,这个时候还不知道别名是什么。group by子句排序
group by子句默认是无序的, 可以通过order by子句进行排序
在where子句中使用聚合函数
只有在select, having, order by三个子句中能使用聚合函数
总结每个子句阶段产生的数据内容:
执行顺序:from -> where -> group by -> having ->order by
from : 选出表中的行数据
where: 对行数据进行过滤,得到过滤后的行数据
group by : 行数据进行分组,得到组数据, 一个分组列对应多行数据
having : 对组数据记性过滤,
3.3 having为聚合结果指定条件
where用来过滤行数据,having则是用来过滤组数据的,因此having子句的书写和执行顺序都是在group by子句后面。
书写顺序:select -> from -> where -> group by -> having
执行顺序:from -> where -> group by -> having -> select
- (from->where)从表中读取数据,并且过滤出符合条件的行数据
- (group by - having)对过滤出来的行数据进行分组,并且过滤出符合条件的组数据
- (select) 对过滤后的组数据进行查询动作
having子句和select子句都是在聚合数据之后, 所以having子句中能使用的元素和select子句也是一样的,having子句只能读组数据进行过滤:
- 常数
- 聚合函数
- group by聚合列
3.4 order by排序
select出来的数据只要不指定顺序,都是无序的,不进行排序的话很可能每次执行的结果的排列顺序都不一样。
ASC:升序 DESC:降序
书写顺序:select -> from -> where -> group by -> having -> order by
执行顺序:from -> where -> group by -> having -> select -> order by
3.4.1 多个排序列
当一个排序列中有多行数据的时候,那这多行的数据就可能是无序的, 这个时候可以再指定一个排序列做更精准的排序。
当指定多个列进行排序的时候,会优先使用左侧的列进行排序,如果这个列存在相同的值的时候便会参考右边的排序列做进一步的排序。
3.4.2 NULL值的排序
在前面说的NULL值不能参加运算符运算, 因此排序列中NULL值的集合会出现在开头或者结尾,具体出现在哪个地方有具体的DBMS决定。
mysql中可以在排序的列名前加上负号。
3.4.3 别名的使用
前面说过group by不能使用别名, 原因是因为在执行过程中group by子句执行在select 子句前面了,所以会失败, 而order by执行是在select 后面。
3.4.4 order by子句中可以使用的列
- 在select 子句中未包含的列,但是在表中的列也可以进行排序
- 可以使用聚合函数进行排序
列编号的排序使用 - 不建议
select 子句中的列从左到右每个列都是有编号的,在order by中可以直接使用列号表示列,但是不建议使用,因为不利于阅读,同时sql-92规范中明确指出该功能后面会删除。
四. 数据更新
4.1 数据插入
基本语法 : insert into <表名> (列1, 列2, ...) values (值1,值2,值3,...);
4.1.1 省略列
当进行全列插入的时候,可以省略列名,只指定表名就可以了。
Insert into 表名 values (值1,值2,值3,…);
4.1.2 插入默认值
插入默认值有两种语法:
- Insert into 表名 values (值1, DEFAULT, 值2….);
- Insert into 表名 values (值1,,值2);
建议使用第一种方便阅读。默认值可能的数据:列有DEFAULT约束的时候为约束值,没有的时候为NULL,如果有NOT NULL约束的话就报错。
4.1.3 表数据复制
语法: insert into 表名(列1, 列2,… )select …. from … group by … having … order by…;
Insert … select 主要可以用来做数据备份。
4.2 数据删除
基本语法 delete from 表名
删除表数据:delete from 表;
删除指定数据:delete from 表 where xxx;
4.3 数据更新
基本语法:update 表 set 列=值 where xxx;
对NULL进行更新:直接使用NULL关键字即可。
4.4 事务
事务语法
1
2
3
4
事务开始语句;
DML语句1;
DML语句2;
事务结束语句(commit;或rollback;)
对于事务开始语句并没有明确的语句:
MYSQL : START TRANSACTION;
SQL SERVER/ POSTGRE SQL : BEGIN TRANSACTION;
ORACLE, DB2 : 无。
4.4.1 事务什么时候开始?
上面可以有的DBMS并没有定义sql开始的语法,实际上在SQL规范中有说明可以指定一种静悄悄的事务。
实际上在各个数据库产品DBMS的实现中,事务都是不需要显示指定开始的, 因为大部分在建立连接的时候就已经开始了事务了。那么数据库是如何区分各个事务的边界的呢?
- 每一条sql语句都是一个事务(自动提交打开)
- 第一次commit或者rollback的时候,之前的操作就作为一个事务。
4.4.2 ACID
注意ACID针对的生效对象是事务。
- A(Atomicity):原子性, 指的是一个事务中的DML语句要么同时执行,要么都不执行。
- C(Consistency):一致性,指的是一个事务中的处理要满足数据库提前设置的约束。例如主键约束, NOT NULL约束等。违反约束的便无法执行,会进行回滚操作
- I(Isolation):隔离性,指的是多个事务间互补干扰的特性。
- D(Durability):持久性,指的是一个事务一旦结束(不管是提交还是回滚),DBMS都要保证这个时间节点的数据状态得以保存的特性。及时发生了数据库故障,这一部分的数据也需要保证恢复。
五. 复杂查询
5.1 视图
- 视图和表
视图是通过select 语句产生的中间表不会落盘到数据库
表是实际会落盘的。
- 创建视图的基本语法
1
2
3
CREATE VIEW 视图名称(列名1, 列名2, ...)
AS
<SELECT 语句>
要求:
- select 语句在AS关键字后面
- select语句查询出来的列数量必须与视图中的列数量一致。
后面的语句在select的时候就可以直接select这个视图了,并且创建出视图以后,表中的数据更新时,视图中的数据也会跟着更新。
5.1.1 视图查询的执行逻辑
当查询语句中的FROM子句中表名是视图的时候DBMS中执行的逻辑为:
- 先执行视图中的select 语句 - 创建一个基础视图
- 在基础视图上再执行select子句
也就是使用视图的时候,视图并不是一直保存在内存中的, 而是每次查询这个视图的时候会触发一次,也就是通常视图查询实际上需要执行两次以上的select语句。两次以上是因为,这个视图可能是根据别的视图创建而来的,虽然不推荐视图套娃的常见方式。
5.1.2 视图的限制
- 在AS关键字后面的select语句中不可以使用order by语句。
- 不可以对视图进行更新, 因为不知道这个select 语句是怎么生成的视图, 可能这个视图是分组数组
5.1.3 删除视图
DROP VIEW 视图名
5.2 子查询
子查询和视图
视图是将select 语句保存在DBMS中,而子查询就是将这个select 语句直接放在from子句中,就是一个一次性的视图。
子查询作用于from子句中
5.2.1 子查询名称
在子查询中可以套娃式嵌套子查询,同时也可以为嵌套的子查询通过AS关键字指定这个子查询的名称.
1
select * from ( select * from ( select ....) AS 别名1 ) as 别名2
子查询设置别名的意义:方便阅读理解
5.2.2 标量子查询
标量子查询就是只返回一行一列结果的子查询。
用途示例
1
2
select xxx, xxx, xxx from xxx where xxx > AVG(XXX); /*错误示例, where子句中不可以使用聚合函数,from... where...;操作的还是行数据 */
select xxx, xxx, from xxx where xxx > (select AVG(XXXX) from xxx);/*使用标量子查询代替*/
标量子查询的书写位置,几乎所有子句中都可以, select 子句, where子句,group by子句,having子句, order by子句。
5.2.3 关联子查询
关联子查询指的是外层查询和内层的子查询通过某个键进行关联起来。
5.2.3.1 使用场景
查询选取的每一行,都要跟表中的一部分记录组成的集合做比较的时候。
1
select shoppingId, shoppingName from shopping AS a where price > (select AVG(price) from shopping AS b where a.shoppingType = b.shoppingType group by shoppingType);
5.2.3.2 执行顺序
- 外部查询的每行数据传递一个值给子查询
- 子查询为外部查询的每一行执行一次,并返回结果给外部查询
- 外部查询再根据这一行数据的子查询做决策
总结:外层查询的每一行数,内部查询都需要执行一次。关联子查询中的数据流是双向的,而普通子查询的数据流是单向的,内部查询流向外部查询。
六. 函数,谓词与case表达式
6.1 函数
函数种类:
- 算术函数
- 字符串函数
- 日期函数
- 转换函数(用来转换数据类型和值的函数)
- 聚合函数(就是前面说的那5种)
聚合函数就是前面说的那5中,sum,avg,max,min,count. 除了聚合函数外,其他的函数有超过两百个,常用的50-60个。可以通过文档进行查询数据库函数的使用。
算术函数
- ABS(数值) - 绝对值
- MOD(被除数,除数) - 求余
- ROUND(对象值,保留的小数位数) - 四舍五入
字符串函数
Str1 str2 str3 - 拼接字符串; select s1, s2,s1 || s2 AS STR FROM XXXX;- LENGTH(字符串) - 计算字符串长度
- LOWER(字符串) - 小写 UPPER(字符串) - 大写
- REPLACE(完整字符串,替换目标字符串,替换后目标字符串)
- SUBSTRING(完整字符串 FROM 起始index FOR 截取长度)
日期函数
- CURRENT_DATE - 当前日期
- CURRENT_TIME - 当前时间
- CURRENT_TIMESTAMP - 当前日期和时间
- EXTRACT(日期元素 FROM 日期) - 截取日期函数
select EXTRACT(YEAR FROM CURRENT_TIMESTAMP) AS year, EXTRACT(MONTH FROM CURRENT_TIMESTAMP) AS month...
转换函数
- CAST(源值 AS 目标值)
- COALESCE(数据1, 数据2, 数据3…) 将NULL转换成其他值,入参列表中第一个不为
6.2 谓词
谓词与函数:函数返回值可能是数字,字符串和日期等等。谓词也是一个特殊的函数,只是谓词的返回自都是真值(TRUE/FALSE/UNKNOWN)
常用谓词:LIKE, BETWEEN, IS NULL, IS NOT NULL, IN , EXISTS.
使用位置:都是在过滤条件的子句中进行使用。where和having子句。
注意:通常谓词都无法和NULL作比较。NOT IN或者IN在和联合子查询使用的时候不能和NULL一起做运算,不然会什么也取不出来。
6.2.1 LIKE - 部分一致查询
全面学习的比较运算符==都是绝对相同的是否返回TRUE,LIKE则表示模糊匹配,类似正则表达式但是没有正则表达式的模糊匹配这么灵活。
匹配语法:下划线(_)表示一个字符。百分号(%)表示n个以上的字符。
like的模糊匹配主要有三种:前方一致(str%),中间一致(%str%),后方一致(%str)
6.2.2 BETWEEN - 范围查询
SELECT XXX FROM TABLE WHERE XXX BETWEEN 10 AND 100; //包含10和100
SELECT XXX FROM TABLE WHERE XXX>10 AND XXX<100//不包含10和100
6.2.3 IS NULL, IS NOT NULL - 判断是否为空
6.2.4 IN 谓词 - OR 的简便用法
语法:IN(值1, 值2, 值3) 等同于 值1 OR 值2 OR 值3
另一个相反的就是NOT IN
可以将子查询的值作为IN的入参;
1
2
3
select xxx, xxx, xxx from xxx where xxx in (select 单列 from xxx where xxx="00x")
/*实际执行*/
select xxx, xxx, xxx from xxx where xxx in (a, b, c, d);
4.2.5 EXIST
特殊谓词,判定后面的语句是否存在。使用方法,一般是结合子查询进行查询。
EXIST执行逻辑理解:子查询中的条件是否满足。
6.3 CASE 表达式
在java中switch() case 表达式用来表示分歧逻辑。在SQL中CASE表达是也是一样。
CASE WHEN 表达式 then 表达式
WHEN 表达式 then 表达式
WHEN 表达式 then 表达式
...
ELSE 表达式
END
SELECT SHOP_ID,
CASE WHEN TYPE = '上衣' THEN 'A:'||TYPE
WHEN TYPE = '裤子' THEN 'B:'||TYPE
ELSE NULL /*可以省略,默认会自动由ELSE NULL,但建议为了阅读要写上*/
END AS newType /*END关键字不可以省略*/
from table;
6.3.1 书写位置
case是一个表达式,可以返回任何值,因此可以在任何地方使用
七. 集合运算
7.1 UNION 表并集
可以将两个select语句查出来的结果合并成一个表结果集。
1
select a,b from xxx union select c,d from xxx2;
上面这个会把两个表数据合并成一个查询结果,并且通常UNION会去除重复结果。
UNION使用的前提条件:
- UNION两边的表达式结果的列数必须一致
- UNION两边表达式结果的列的数据类型必须一致
7.1.1 Order by子句只能出现在 union的右边
7.1.2 使用 ALL选项保留重复行
select … UNION ALL select …
7.2 INTERSECT 交集
SELECT ... INTERSECT SELECT ...
7.3 EXCEPT 差集
select.. except select …
7.4 联结
上面说的集合运算,并集,交集,差集都是在行数据上的增减。而联结就是在列上的增减,简单点说就是把别的表的列添加到自己的表结果中。当期待的结果存在多个表中的时候,就可以采用联结的方式联结多张表进行选取数据。
7.4.1 内联结 INNER JOIN
基本语法:在FROM子句中指定两张表,并且通过INNER JOIN … ON 指定内联结的键, 多个键可以用 AND,OR等
SELECT ... FROM TABLE1 T1 INNER JOIN TABLE2 T2 ON <联结条件表达式> WHERE XXXX;
书写位置 : FROM 子句和WHERE子句之间。
7.4.2 外联结 OUTER JOIN
外联结与内连接的不同在于,内联结只提取公共部分联结成为一个查询结果,而外联结是在确定了一张表为主表的情况下, 将领一张表的数据列并进来,对不上的数据就使用NULL表示
基本语法与INNER JOIN …. ON 一样,只是多了一个关键字指出主表是哪一个。
1
select ... from table1 t1 LEFT/RIGHT OUTER JOIN table2 t2 on <联结表达式>
7.4.3 三张以上的表的联结
1
2
3
4
5
6
select ...
from table1 t1 LEFT/RIGHT OUTER JOIN table2 t2
on <联结表达式> -- 一级联结,联结t1 t2
left OUTER JOIN table3 t3
on <联结表达式> -- 二级联结,联结 t3
left ....
7.4.4 过时内联结
1
select * from table1 t1, table2 t2 where t1.xxx=t2.xxx;
上面这种也是内联结语法,但是是过时的内联结语法。后续版本会剔除。除此外还有别的弊端:
- 妨碍阅读,无法第一时间知道这是一个内联结还是外联结
- 连接条件放在where子句中,无法快速判断where子句中的判断是联结判断还是选取记录的限制条件。
- 不知道这样的语法能使用多久,应为这个语法已经判定为过时语法,虽然到目前位置还能正常执行。
7.5 CROSS JOIN 交叉联结(笛卡尔积)
7.6 集合运算优先级
INTERSECT优先级最高,UNION和EXCEPT相等。
八. SQL高级处理
8.1 窗口函数
主要是为了OLAP服务的,OLAP为数据库实时数据分析处理的数据库。而窗口函数就是为了实现OLAP添加的标准SQL功能。
1
<窗口函数> OVER ( [PARTITION BY <列清单>] ORDER BY <排序用列清单>);
窗口函数:
- 聚合函数(COUNT, SUM, MIN, MAX, AVG)
- RANK, DENSE_RANK, ROW_NUMBER