一. 简介
什么是io(input/output)?
就是对数据的操作。所有需要操作IO的地方都需要
io相关的知识涉及到哪些方面的?
二. IO指标
【iops】 发生实际io调度的次数,决定一块硬盘的速度的快慢除了看磁盘的速率,iops也是一个很关键的指标, 这个指标影响着你需要打开很多小文件时的速率。
【io速率】 io带宽的速度,就是看每秒钟能读取的数据量。
【io时延】 每次读写io调用的响应耗时用了多久, 机械硬盘主要影响是物理磁头的寻道寻址, 固态硬盘主要影响是磁盘空间的垃圾回收。
三. IO类型
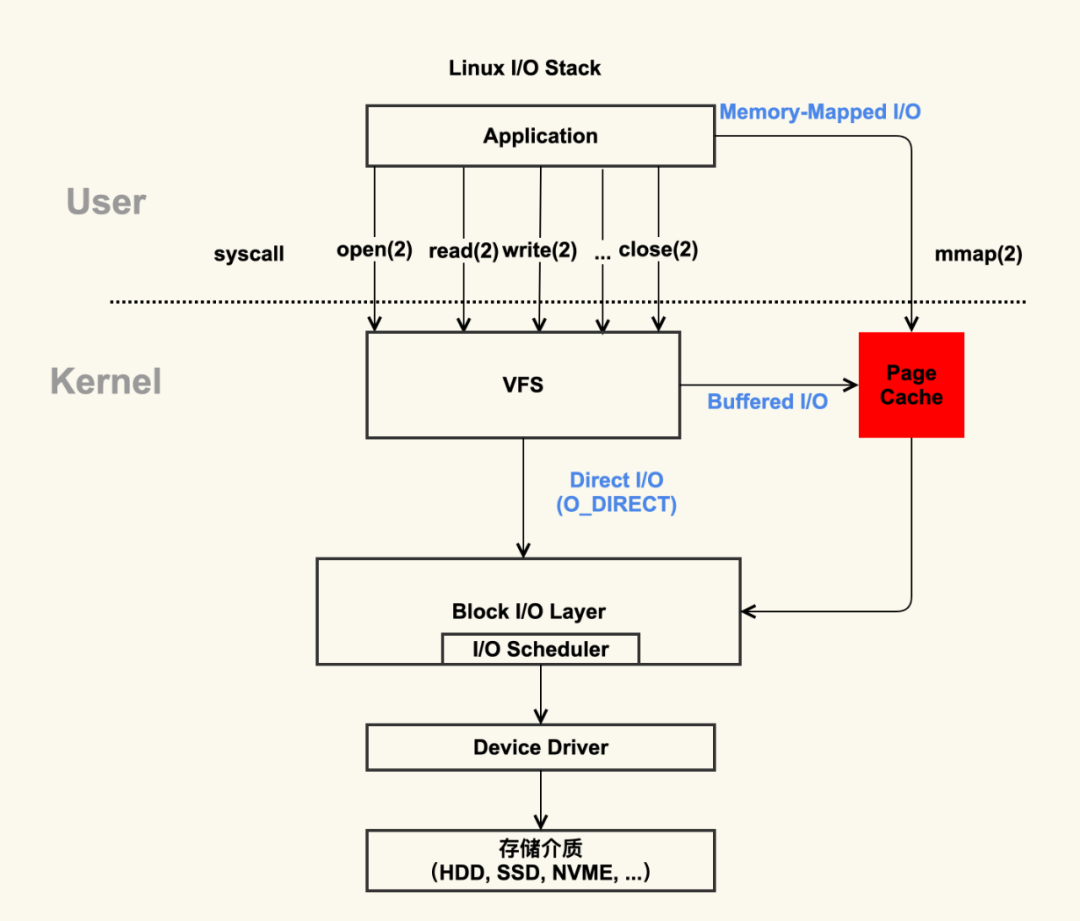
在一个操作系统中,文件数据的来源多种多样,可能来自于本地磁盘,可能来自于网络。本地磁盘,又有各种协议,各种格式,各种集群方式, 网络也有各种不同的网络文件格式。Linux为了屏蔽这部分的差异,让上层的进程无需关系文件的具体来源是什么,向上层的应用提供了抽象的文件接口层封装:VFS(Virtual File System)。
应用读写数据的时候都是调用系统函数对VFS进行read/write。那么操作系统怎么去操作这部分的read/write动作的呢?
从操作系统来看,操作系统对这种读写数据的IO操作主要分成三种, 一种bufferio, 一种是directio和MemoryMapperio
4.1 Buffer IO
bufferio是一种异步IO的形式,应用调用read/write的时候,由系统的page cache进行查看应用的虚拟空间中是否有相应的数据页, 当发现读写的这部分地址的数据页不存在的时候,发生一个缺页中断。
- 当是读的缺页异常时,由操作系统去load这个数据页进page cache中。然后再拷贝到用户空间的虚拟地址空间中
- 当是写的缺页异常时,会向page cache申请page内存,然后再写入到这个cache的数据页中,然后再由操作系统将这个数据页定时定量地刷回磁盘中。
4.2 Direct IO
Direct IO则是应用在调用read/write文件的的时候,通过指定一个标志位,将程序内存作为Block层读写的内存地址,而不是通过page cache进行读写。
4.3 Memory-Mapper IO
直接将进程的内存地址映射到page cache中,少了从内核空间中再拷贝回进程的内存地址空间中的步骤
总结,这三种的IO方式相同点都是通过Linux Block层进行操作IO。不同的是他们在通过Block层进行读写的时候, Block层读写的地址是不同的,buffer io和mmp io都是让block层对page cache的内存进行读写, direct io是直接让block层对进程内存进行读写
五. Linux Block层发展
Linux的Block层主要负责应用程序与底层存储之间的转换。Block通过提供统一的接口给内核的库,应用程序通过操作系统调用,将IO请求提交到Block层。 Block层将这些提交的IO数据块缓冲在一个队列中,这个队列就是请求队列。主要的功能就是对IO请求的暂存,合并以及决定以何种顺序梳理IO请求。这里面主要设计到两种实现single-queue架构和mutil-queue
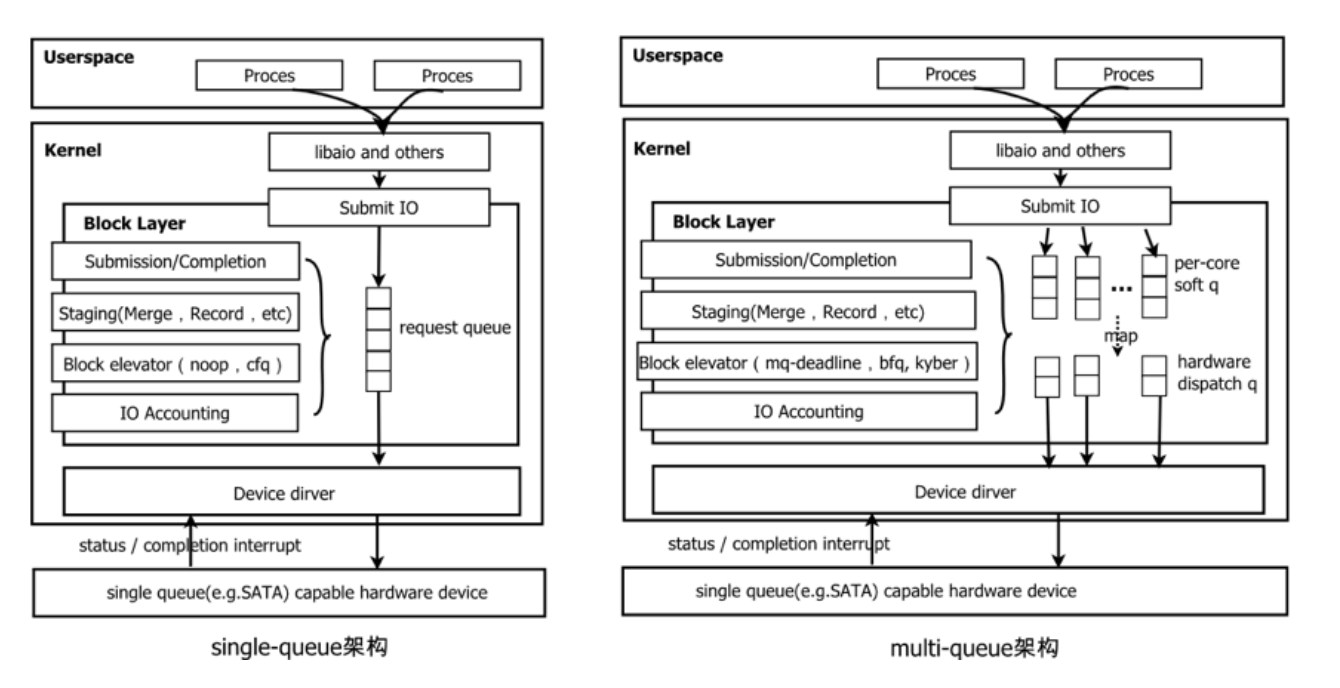
5.1 单队列调度器
单队列调度器主要有noop, deadline和cfq这三个。由于早期的存储设备物理磁盘只支持单队列,所以一开始的IO调度设计也是 单队列的,只需要对这个单队列的限速整理统计便可以了。
单队列调度器设计的考量指标主要有三个:
5.1.1 noop
noop,也叫做None,就是对这些IO请求没有过多的干预。采用FIFO的策略,定时定量将IO请求进行合并打包发给驱动程序处理, 但是它不会对请求进行排序。适合新兴的闪存存储设备SSD,应为他们不需要排序再整合随机IO,他们的IO速度足够快。
5.1.2 deadline
deadline调度器如其名,设计思想是尽最大可能让每个io请求都有一个deadline,尽可能在deadline之前完成io请求。
这个调度器会对队列中的IO请求根据扇区地址进行排序整合,由于io请求的数据有可能集中在某些扇区中,导致后面的请求一直被合并到前面去, 于是后面的请求就有可能会超时甚至被饿死,为了防止这种情况的发生,让别的扇区的数据也能进行读写,它通过实现四个队列,正常的读写队列, 超时的读写队列。优先处理调度超时的读写队列,然后再处理正常的读写队列。当发现正常的读写队列中有快超时的IO请求时就会移动到超时的读写队列中。
5.1.3 cfq
complete fair queue绝对公平队列。通过为每个进程维护一个队列,同时又维护一个全局公用的队列,cfq会根据进程的优先级进行调度进程的IO, 并且保证会让各个进程都有一样的”虚拟IO时间”,而不会饿死某些进程的IO请求。这个虚拟IO时间跟进程调度策略里面的cfq调度策略的”虚拟CPU时间”原理是一样的。
计算公式可以简化理解为:虚拟IO时间 = 实际IO时间 * 进程优先级PR值。由于虚拟时间是一样,进程优先级越高,PR值就越小。于是实际的IO时间便越大。
5.2 多队列调度器
【多核CPU给单队列带来的性能挑战】
1.多核对单cpu的锁竞争 试想一下,你现在碰到了这样的性能瓶颈问题,因为核数的增多,每个核向队列添加io请求的时候都需要锁一下队列,随着核数越来越多,竞争越来越激烈, 增加的核数因为这个锁竞争的问题并没有像设想的那样让机器的性能跟核数线性倍增性能,这个时候要怎么解决这个性能问题呢?
首先,我们可以分配多个队列,让每个NUMA节点一个队列,或者甚至每个cpu核一个队列,那样就没有锁竞争了。最后调度这些IO请求的时候从这些队列里面拿出一些IO请求出来, 然后再进行合并成一个批量的io请求给磁盘队列。
其次,如果硬件也支持并发队列来并发地处理io请求那就更好了,那每个核心的请求只需要进行适当的合并就可以了,真正从硬件层面实现并发IO的处理。
事实上Linux内核上也是这样演化的,在最开始设计IO调度的时候,一开始设计的是单队列的,即使单队列的cfq调度器是有多队列的, 但是cfq的多队列和多队列调度器的多队列的设计目标是不一样的。
多队列调度器主要维护两组与硬件相关的队列, 软件层面的暂存队列和硬件层面的调度队列。
暂存队列基于CPU核数进行分配,每个cpu核或者NUMA节点一个队列,这些队列的添加通常是由一个自旋锁控制,因此这些队列每个都可以有自己的队列管理器。 调度队列基于存储硬件特性,可能只有一个,也可能多达2048个(或者由系统配置的支持多少个中断源决定)。Block IO层会为每个调度队列分配一个上下文, 并且在将请求发送给驱动程序处理的时候也会带上这个上下文。
2.中断处理的增加 当IOPS较大的时候,中断次数就会增多。现在系统处理中断的方式都是硬件中断绑定在一个核上,然后再将软中断转发给其他的核处理。完成一次IO操作就需要一次硬中断, 一次软中断还有应用程序上下文切换的开销。
3.cpu核之间的跨缓存访问增加 当发生提交IO请求与处理IO完成(硬中断)不是一个核的时候,就会使请求队列的锁竞争现象更加严重。并且还需要访问其他的核的高速缓存。
【硬件急速发展带来的挑战】
由于以前存储的瓶颈都是在硬件层-物理磁盘。应为物理磁盘的数据存储和读取都需要移动磁臂和旋转磁盘片。通常HDD通过旋转磁盘盘片进行顺序读取,速度较快。 但是需要移动磁头进行随机读取,磁头的移动速度是很慢的,以前的一代一代的算法,中间件,系统都是基于这两个特性进行设计的。 但是随着SSD的出现,顺序IO与随机IO的差别变得越来越小,并且SSD内部还实现了真正的并行IO操作。HDD的随机IO需要几十毫秒,而SSD的随机IO只需要微秒级别。 因此单个SSD能达到百万级别的IOPS, 而HDD只能达到数百次的IOPS。
随着存储设备的飞速发展,存储性能瓶颈已经从硬件转移到了软件层面。也就是Linux的Block层,不管有多少个核提交IO请求,到了Block层的速度只能达到百万级别。 对于现在的IO设备来说,硬件的处理速度已经逼近了软件层的处理极限了,甚至已经超过了。
5.2.1 mq-deadline
deadline的多队列实现
六. 内核中磁盘相关配置查看与设置
6.1 调整内核参数的几种方法:
- sysctl命令,修改/etc/sysctl.conf 配置文件,然后通过sysctl -p命令生效
- /proc/sys/, 这个系统内核参数的内存映射文件夹,sysctl中所有可配置的内核参数都会在这里以目录和文件的形式存储,改变即时生效。
- /sys/*, 这个目录将内核态进行模块化后,以目录和文件的形式存在,在这里修改的值也会即时反馈要内核态中。
/proc/sys/目录与内核参数之间的映射关系,把目录换成’.’号就是系统内核参数了。
修改/proc/sys/ 是临时修改内核参数,重启后失效
修改/etc/sysctl.conf是永久生效,重启后也还在,不重启生效的方式sysctl -p
映射关系/proc/sys/net/ipv4/ip_forward =》 net.ipv4.ip_forward
6.2 查看当前系统支持的调度策略
1
dmesg |grep io schedulder
dmesg |grep -i scheduler
[ 3.267129] io scheduler noop registered
[ 3.267134] io scheduler deadline registered (default)
[ 3.267173] io scheduler cfq registered
[ 3.267178] io scheduler mq-deadline registered
[ 3.267182] io scheduler kyber registered
6.3 查看当前块设置的调度策略
1
2
3
lsblk 查看当前系统块挂载情况
cat /sys/block/*/queue/ 查看某个设备块的调度策略
建议同一个磁盘设备上所有的分区都是用同一种策略。
6.4 page cache相关配置
| 参数 | 单位 | 说明 |
|---|---|---|
| vm.dirty_writeback_centisecs | 1/100秒 | writeback机制定时刷盘的时间,如果刷盘的时间超过了这个间隔会sleep 1s |
| vm.dirty_expire_centisecs | 1/100秒 | 写进page cache的数据多久会被标记为脏数据,默认为30s,只有被标记为脏数据在下一个周期pdflush才会将这个脏数据进行刷盘 |
| vm.dirty_backgroud_ratio | 默认10 | writeback机制定量刷盘的数据量比例,达到这个数据量以后会唤醒pdflush进程进行刷盘,这个比例指的是脏数据可用内存空间的比例(free+cache-mappered) |
| vm.dirty_ratio | 默认20 | 表示脏数据到达这个比例以后,将阻塞所有的写操作,直到pdflush刷完了所有的脏数据进盘里面为止。这是对上面设置的一个补充,如果写数据很快,上面唤醒的刷盘还没完有来了更多的IO数据的时候作保护。 |
page cache的writeback机制就是异步写机制,这个机制有个风险就是没刷盘前在内存中的数据加入发生宕机会丢失,在一些数据敏感的系统上可以吧这个机制ban掉,或者使用直接内存进行访问磁盘。
6.5 中断处理配置
七. 相关的命令
| 命令 | io作用 | 常用 |
|---|---|---|
| top | 查看iowait,硬中断核软中断 | |
| iotop | 查看进程io | |
| vmstat | 查看内核的iowait,swap区使用 | |
| iostat | 查看存储硬件分区的读写 | |
| pidstat | 查看进程/线程的读写 | |
| sar | 查看page cahche和系统bufferio的运行情况统计 |
详情查看《linux常用命令》
参考