一. 编译原理的基本概念
语言由句子组成,句子由子句和词汇符号组成。一门语言的编译器或者解析器,必须识别出这门语言的所有有效句子,短语和子短语。 识别语言的程序叫做语法分析器。
1.1 词法分析器
处理将单个字符组成的的符号和单词的程序叫做词法分析器。它只负责识别单词和符号,
1.2 语法分析器
语法分析器负责通过将词法分析器中的符号和单词去识别句子的结构。
1.3 文法
二. Antlr
2.1 Antlr是什么?
Antlr就是一个编译器工具,通过Antlr可以帮助你构建出一个完整的编译器。
Antlr使用流程
- 编写Antlr的语法规则文件,相当于告诉Antlr你想构建的编译器的语法长什么样子
- 通过Antlr工具(ide插件或者命令),根据你的语法文件自动生成对应的分析器
- 在你的编译器中,通过Antlr的编程模型调用对应的api构建词法流,语法流,然后再通过观察者模式, 在特定的语法中回调你的接口实现编译器的语法解析。
Antlr语法分析流程
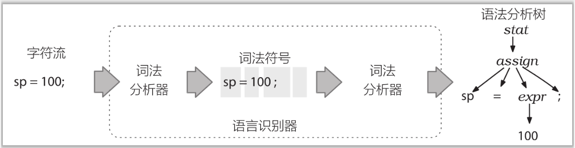
2.2 Antlr元语言语法
一般的语言都是有一下的几种模式组成的:
- 序列sequence
- 选择choice
- 词法符号依赖token dependency
- 嵌套结构nested dependency。
元语言就是用来描述这几种结构的,元语言的定义自上而下就是由序列组成。
元语言语法
语法名/词法名 : 备选分支(语法名/词法名) | 备选分支(语法名/词法名) ;
2.2.2.1 语法规则
- 大小写
- 语法(文法):统一用小写
- 词法名:统一用大写
- 个数匹配
+一个或多个元素,标准写法(INT)+ , 也可以省略成INT+*零个或多个元素,标准写法(INT), 也可以省略成INT?零个或者一个元素
- 模糊匹配
ID : [a-zA-z]+
匿名词法规则
2.3 歧义处理
2.3.1 标识符歧义处理
expr : 'enum' ID '{' '}'
ID : [a-zA-Z]+
像上面的例子语义上,enum既可以解析成expre规则中的‘enum’,也可以解析成ID,那么这种有歧义的语法在antlr 中是怎么处理的呢?
antlr在元数据的解析中会进行排序,对于语法中的定义的常量字符串会被隐性地解析成词法规则,并且放在语法规则后, 词法规则前。
ANTLR总是隐式地把字符串常量解析为词法规则,并放在所有的词法规则前面。
也就是可以理解成 语法定义中,只有词法规则名,对于没显式标识的字符串,则会解析成匿名词法规则。
实际运行时的规则会类似有:
expr : 'enum' ID '{' '}'
隐式词法 : 'enum'
ID : [a-zA-Z]+
转义字符匹配:\\表示单个斜杠\
| expr: “xxx=0 | xxxx<0” |
Expr :
2.4 环境搭建
Altlr主要分两个部分
- 一个是ANTLR 4 Tool工具包,主要负责通过语法文件生成词法分析器,语法分析器等java类
- 另一个是ANTLR 4 Runtime包,Antlr运行引擎,运行时协调分析器做回调等
2.4.1 本地环境搭建
开发时环境我们主要需要的是ANTLR 4 Tool工具,在maven仓库中下载,然后本地直接运行 java -jar antlr-xx.jar. 为了方便我们平时生成调试,我们直接在~/.bash_profile中配置别名 alias antlr="java -jar /Users/lee/tools/antlr/antlr-4.5.jar" 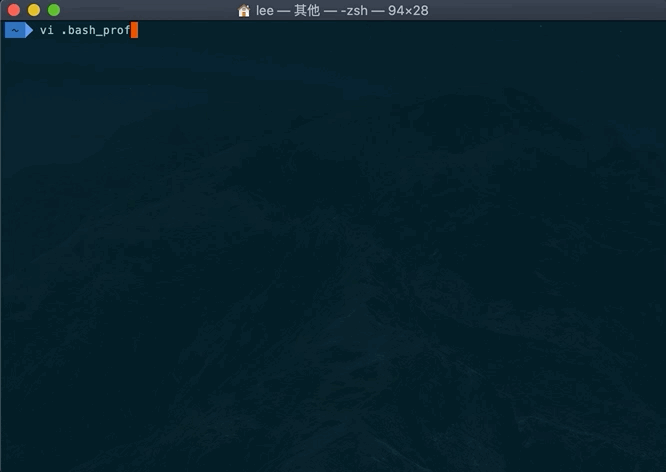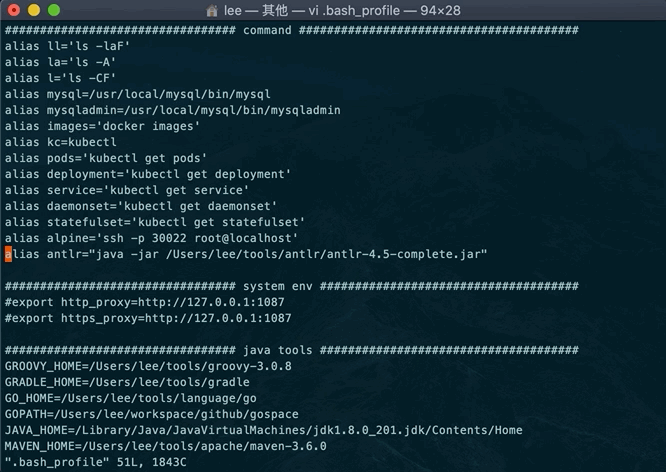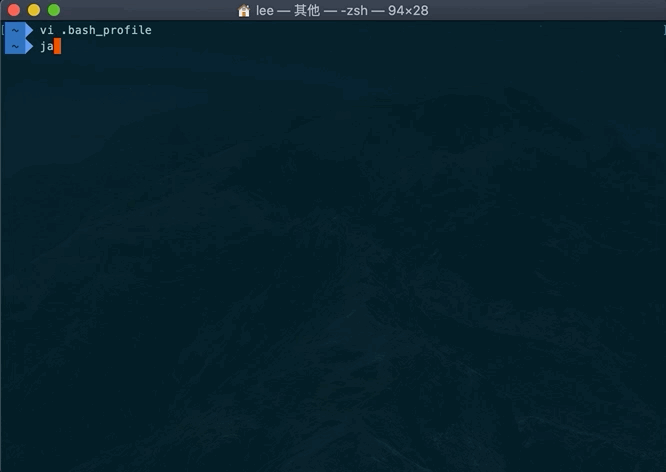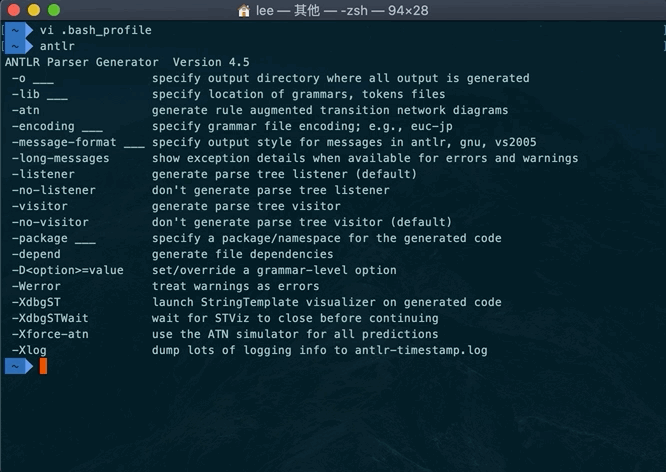
2.4.2 ide环境搭建
这里选择idea作为开发工具,其他的IDE也是类似的需要安装一个antlr的插件即可。 在IDEA的 preference -> plugins -> 在市场中搜索antlr即可,安装ANTLR v4 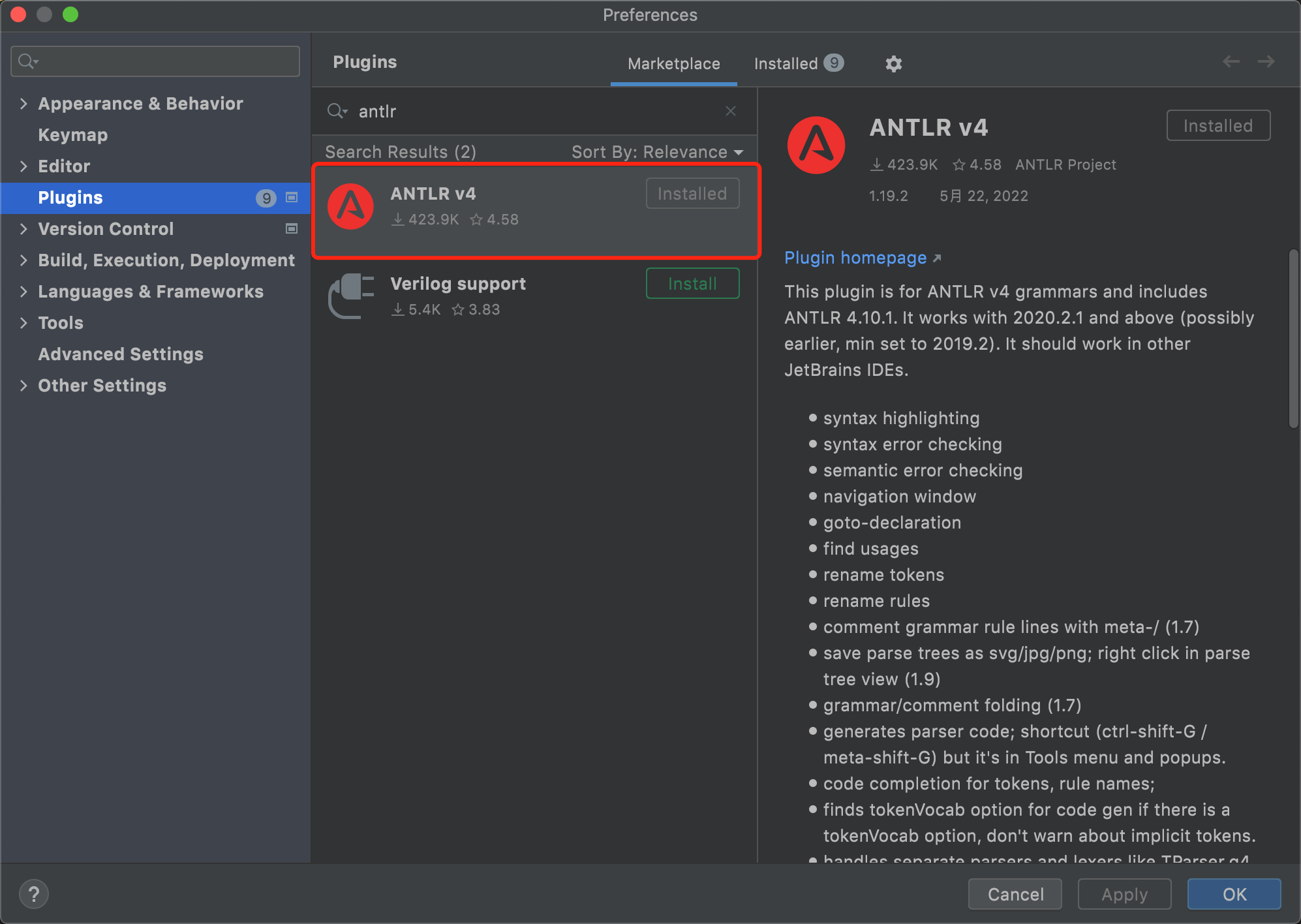
插件使用 ide中的插件主要有两个用途:
- 根据语法文件,生成实时语法树
- 为语法文件生成词法分析器,语法分析器
打开编写好的语法文件,然后右键就可以看到插件使用的选项了。
注意:语法测试是右键处于那个语法名便测试哪个语法,例如下图中,我的光标是放在compilationUnit,那么语法测试 就是在compilationUnit中开始 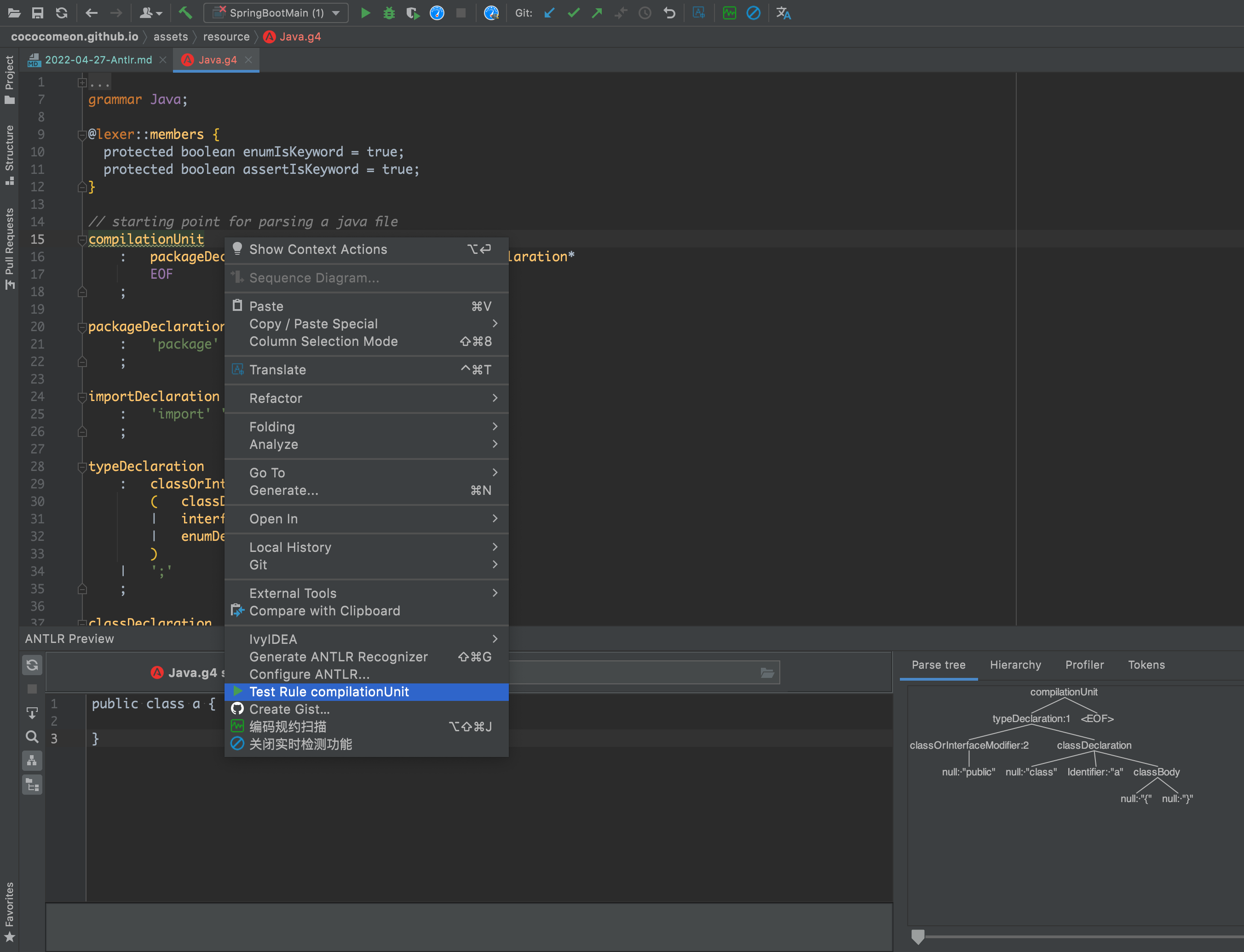
三. 编程模型
词法分析器(lexer):
maven 编码UTF-8的不可映射字符 原因:工作空间中原来的编码为GBK, 然后新打开的工作空间是UTF-8编码的,改动文件写入了UTF-8字符
四. 辅助工具
IDE插件 写语法文件的时候,想要实时地测试一个语法输入会解析成什么样子?