一. 什么是正则表达式
要匹配一个字符串,有哪些元素可以描述这个匹配的请求长什么样子呢?如何表达自己的匹配需求呢?
正则表达式就是一套描述匹配需求的规则定义,设定一套通用的标准,不同的语言都能根据这个标准就能理解你想匹配的字符串长什么样。可以将不同的程序语言想象成现实中的语言, 匹配的字符串就是你要找的一个人, 那么如何通过对方的语言告诉对方你要找的人张什么样子,有什么特征,眼睛嘴巴肤色头发等,这些特征就是正则表达式的规则。
需要注意的是每个语言支持的正则表达式都不是完全一样的,使用具体的语言的时候要参考具体的语言的正则表达式说明,就好像现实里一些词是每个语言里面都有的东西, 例如头发,眼睛,嘴巴,每个语言都能找到对应的翻译。但是有的词语自己这项语言作为方言特有的词语, 例如粤语里面的“xxx”。java,python,shell,go等等都有自己的正则表达式的支持,语法也不尽相同。下面介绍一些常用且通用的规则类型,但是具体的表示语法要根据具体的语言进行查阅。
通用的正则表达式的规则主要由以下的类型:
- 元字符匹配(主要就是ASCII码表中的各种字符类型的匹配,可见字符,不可见字符,特殊字符)
- 出现次数匹配(0次,1次,多次)
- 位置匹配(行首,行末)
- 分组和后向引用(提取匹配的字符串)
- 匹配模式(贪婪,最小匹配)
正则的处理主要有两部分内容:
- 我们能怎么匹配想要的内容
- 匹配到想到的内容后我们能做什么操作
二. 通用正则表达式
元字符匹配-普通字符
.:匹配任一字符(换行符除外)[a-zA-Z]:匹配a到z任一字符[^abc]:匹配任一不是abc的字符次数匹配
*:匹配前面字符任意次?:匹配前面字符0或1次+:匹配前面字符至少1次{m,n}:匹配前面字符至少m次,最多n次位置匹配
^:匹配字符串的开始位置,在中括号中使用时表示不接受方括号表达式中的字符集合[^abc]$:匹配字符串的结尾位置分组和后向引用
():表示一个子表达式,\1 \2 \3就叫做后向引用,表示第几个表达式所匹配到的内容
上面是常用的标准正则表达式的规则定义描述, 还有一些不常用的没有列举出来的包括
- 不可见字符,包括什么空白符,换行符号,制表符等等
- 特殊符号,例如上面表示语法的那些符号
* . ?等等
这里以shell中的正则表达式作为作为例子演示匹配分组。
三. grep 命令
1
grep [option] [PATTERN] [file...]
option部分
| option | 所属类别 | 说明 |
|---|---|---|
| -E | Matcher类型选择 | 使用拓展Pattern |
| -v | 匹配控制 | 反转匹配 |
| -i | 匹配控制 | 忽略待匹配的字符大小写 |
| -l | 输出控制 | 输出匹配的内容,默认输出文件名 |
| -r | 文件选择控制 | 递归选择 |
四. sed命令
sed(Stream Editor)的原理是将待匹配行输入进行操作,然后输出到标准输出流中。
1
sed [OPTION] script [inputfile]
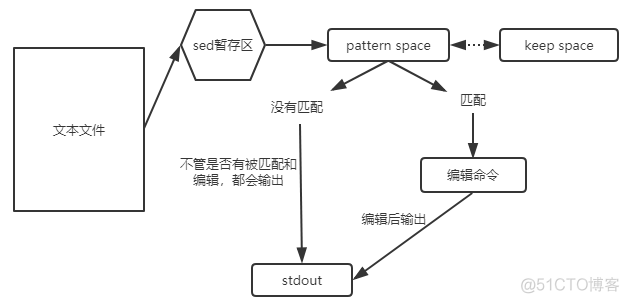
4.1 option部分
| option | 说明 |
|---|---|
| -n | 仅输出匹配的模式空间内容 |
| -r | 支持拓展的正则表达式 |
| -i | 直接编辑源文件 |
4.2 script部分
1
sed [option] "定界+编辑" file
script主要有两部分内容:
- 一个是定界,就是匹配仅模式空间的内容行怎么选定。规则有正则表达式定界,行数定界,行数步进定界。
- 另一个是编辑,就是对这些选中的行做什么操作,替换,在后面插入,在前面插入,在匹配行的下一行插入
【定界-全文匹配】 定界部分值为空,就是全文匹配。 sed "a line1\nline2" file 或者 sed "//a line1\nline2" file
【定界-范围匹配】
| 定界方式 | 说明 | 示例 | 示例说明 |
|---|---|---|---|
| n,m | 第n行到m行的内容 | sed -n “1,2p” file | 匹配1-2行到模式空间中,并且打印出来 |
| n,k+ | 第n行开始,往后的k行 | sed -n “1,+3p” | 匹配第1行开始,往后的3行,并且打印出来 |
| n,/pattern/ | 第n行开始,至pattern匹配到的那一行 | sed -n “1,/maven/p” | 匹配第一行开始,直到匹配到maven的行,并且打印出来 |
| /pattern/, /pattern/ | 第一个pattern到第二个pattern的行 | sed -n “/article/, /maven/p” |
【定界-单行匹配】
| 定界方式 | 说明 | 示例 | 示例说明 |
|---|---|---|---|
| n | 匹配第几行 | sed -n “1p” file | 匹配第一行,并且打印 |
| /pattern/ | 模式匹配到的所有行 | sed -n “/patter/p” file | 打印出匹配的行 |
【编辑】
| 编辑命令 | 说明 | 示例 | 示例说明 |
|---|---|---|---|
| d | 删除整行 | sed “/pattern/d” file | 删除匹配行 |
| a | 在界定行的下一行append | sed “/pattern/a line1\nline2” file | 在匹配行的下面append新的两行line1和line2 |
| i | 在界定行的上一行append | sed “/pattern/i line1\nline2” file | 在匹配行的上面append新的两行line1和line2 |
| w | 将匹配行保存到特定的文件中 | sed “/pattern/w /temp/fstore” file | 将匹配行保存到/temp/fstore文件中 |
| r | 读取指定的文件内容,添加到匹配的行后面 | sed “/pattern/r /etc/config” file | 将/etc/config中的内容,append到file中模式匹配的后面 |
| s | 匹配的内容做条件替换 | sed “/pattern/s/$/abc” file | 将匹配的内容的末尾替换成abc,也就是在匹配的字符串后面插入 |
| g | 全局替换 | sed “s/abc/hhhh/g” file | 界定符为空,即全文扫描,将abc替换成hhh |
| p | 打印 |
4.3 高级用法
对同一个文件执行多个模式操作有三种方式可以实现:
- 通过管道符,来顺序执行完多个模式操作
- 通过多个-e参数来指定多个多个模式操作
- 单个sed命令中通过分号分割多个模式操作
五.awk命令
参考:
https://blog.51cto.com/u_15257216/5417009