一. 字符编码基本概念
1.1 字符集
什么是字符集? 字符集就是一系列字符的集合。就像一个字典,根据某一个码值就能找到对应的符号。 Unicode就是国际上最通用的字符集。 GB2312,GBK,GB18O30是我国中文的国标字符集规范。
- GB2312为1980年发布的国标基本集,只有简体字,双字节编码兼容ASCII码标准,有空白区允许拓展造字
- GBK为1995年发布的,兼容2312,根据2312的拓展规范收录了big5的所有的繁体字
- GB18030为发布了两次,分GB18030-2000和GB18030-2005。GB18030采用变长编码,1,2,4字节进行编码
1.2 字符编码
什么是字符编码? 上面的字符集就是规定的了这些字符的码值都有一个一一对应的符号,但是没有定义这个码值在软件系统之间怎么 交换。因为最后传输记录的都是一串串字节流,所以有了码值以后,就需要一个编解码规则,并且每个平台系统都支持 这个编码规则,在一串字节流在不同的平台或系统中传输的时候都能根据这个编解码规则解析出正确的码值,然后再根据 这个码值显示出正确的字符。如果两边的编解码规则不一致就会导致解出来的码值不对,显示的符号也不对,就会变成乱码。
上面说的这些字符集都有自己对应的编码规则。
| 字符集 | 编码规则 |
|---|---|
| Unicode | UTF-8,UTF-16,UTF-32 |
| GBK | GBK |
二. Unicode 详解
Unicode出现的原因 Unicode出现前没有一个编码方案能解决跨语言跨平台的文本转换处理要求。为了解决传统编码的局限性, Unicode收纳了世界上所有语言的字符,给每个字符都有一个码值。 Unicode字符集的最初的设计初衷是码值为固定长度16bit的,2个字节。理论上能支持$2^16$个字元,也就是65535个字。 但是这并不能支持世界上所有的文字字符。于是从Unicode 2.0开始便开始通过划分平面的方式支持增补字符。3.0正式增补了第一批字符。
2.1 unicode平面
Unicode根据码值的大小进行排列分组,每一个组称为一个平面,每个平面里面包含了$2^16$个,也就是65535个字符。 其中第一个平面是各类语言中最常使用的字符集合平面,也叫基本多语言面。BMP(Basic Mutillanguage Plane)。
现在Unicode的字符编码范围为:0x0000 - 0x10FFFF, 可容纳一共一百一十多万个字符,分为17个平面 0-16
| 平面编号 | 码值范围 | 平面说明 | 中文名 |
|---|---|---|---|
| 0 | U+0000 - U+FFFF | BMP(Basic Multilingual Plane) | 基本多文种平面 |
| 1 | U+10000 - U+1FFFF | SMP(Supply Multilingual Plane) | 增补多文种平面 |
| 2 | U+20000 - U+2FFFF | SIP(Supply Ideographic Plane) | 增补表意文字平面 |
| 3 | U+30000 - U+3FFFF | TIP(Tertiary Ideographic Plane) | 表意文字第三平面 |
| 4-13 | U+40000 - U+DFFFF | 未使用 | |
| 14 | U+E0000 - U+EFFFF | SSP(Supply Special-purpose Plane) | 特别用途平面 |
| 15 | U+F0000 - U+FFFFF | PUA-A(Private Use Area-A) | 私人平面-A |
| 16 | U+100000 - U+10FFFF | PUA-B(Private Use Area-B) | 私人平面-B |
在Unicode中可以将字符大体分为两类,一般在编程中也是这样区分,一个字符,要么是基本字符(BMP),要么是拓展 字符(1-16平面)
2.2 码点
官方术语叫code point,我们口语中常叫码点,码值,码位,即文字符号的在字符集中的编码位置,也就是一个码值,Unicode字符集的码值从0x0000 值 0x10FFFF, 在这中间的任意一个符号对应的值就是它的码点,码值,码位。
表示一个码值要多少个字节? 我们知道1个16进制需要4bit表示,两个16进制就是8bit(1byte)了,由上面的平面的码值范围能够看出, BMP平面的码值只需要两个字节便可以表示一个码点,其他的平面的需要3个字节才能表示一个码点。
2.3 码元
官方术语叫code unit,口语交流常叫码元(编码单元),指的是已经进行了字符编码的最小比特组合单元。对于UTF-8来说 码元就是1字节,UTF16就是2字节,UTF32就是4字节。
码元存在的意义是什么呢?为什么需要码元呢?
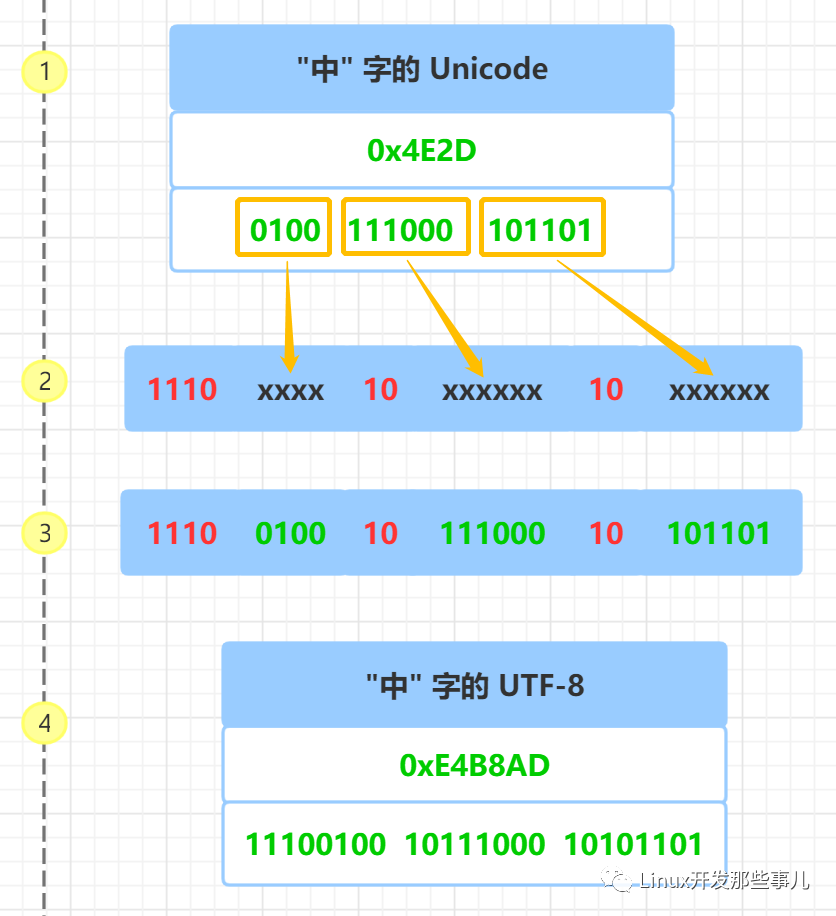
三. UTF-8编码
utf8为一种变长编码,将unicode字符集编码映射成字节流,进行传输传递。
| Unicode码点 | 码点有效字节 | 平面编号 | UTF-8编码 | 编码字节 |
|---|---|---|---|---|
| U+0000 - U+007F | 1 | 0(BMP) | 0xxxxxxx(ASCII码) | 1 |
| U+0080 - U+07FF | 1-2 | 0(BMP) | 110xxxxx 10xxxxxx | 2 |
| U+0800 - U+FFFF | 2 | 0(BMP) | 1110xxxx 10xxxxxx 10xxxxxx | 3 |
| U+10000 - U+10FFFF | 3 | 1-16 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | 4 |
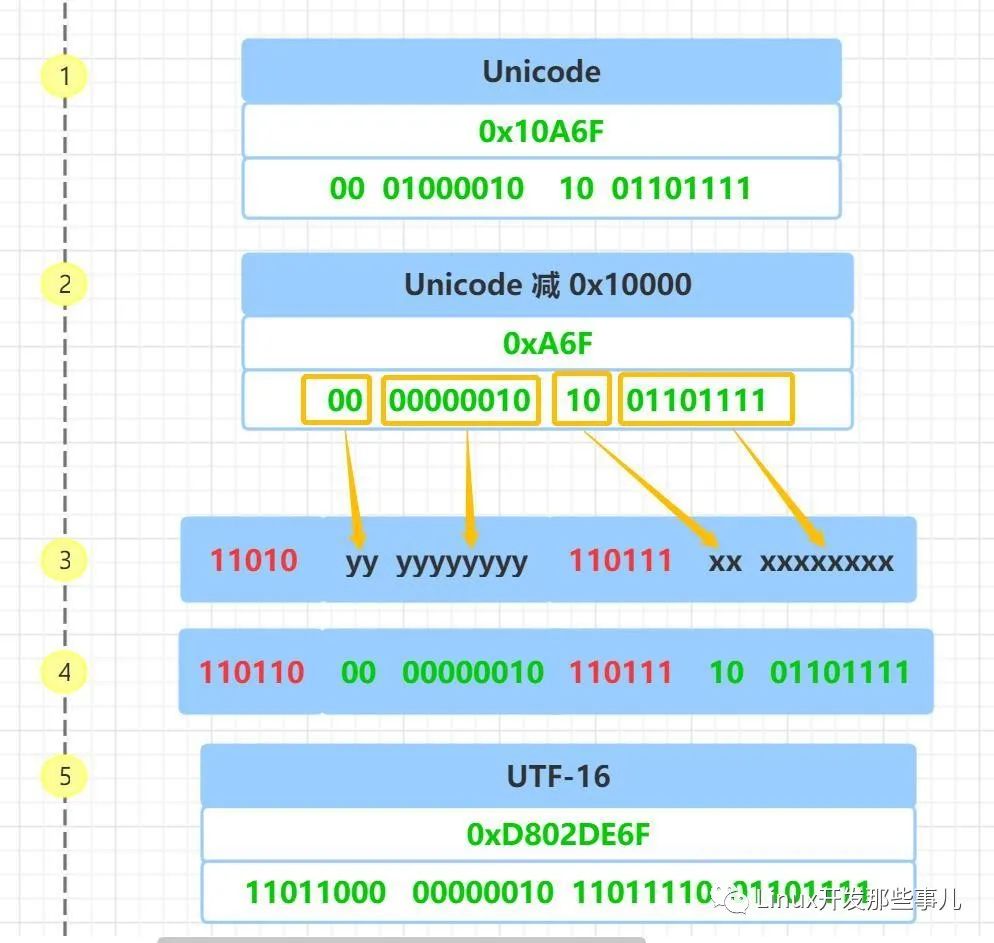
四. UTF-16编码
UTF16也是变长编码类型,采用2字节或者4字节进行标识,UTF16中2个字节是一个码元。
| Unicode 码点 | 码点有效字节 | 平面编号 | UTF-16编码 | 字节数 |
|---|---|---|---|---|
| U+0000 - U+FFFF | 2 | 0(BMP) | xxxxxxxx xxxxxxxx | 2 |
| U+10000 - U+10FFFF | 3 | 1-16 | 110110xx xxxxxxxx 110111xx xxxxxxxx | 4 |
对于基本平面0的字符,utf16直接使用两个字节进行表示,不进行任何转码操作。 对于增补平面的字符,utf16使用4个字节表示一个3字节的unicode码点。
utf16得以实现原理:第一个单元(U+D800 至 U+DBFF)和第二个单元(U+DC00 至 U+DFFF)作为保留码点值留给UTF16编码使用, 也就是BMP平面不允许有字符使用U+D800 至 U+DFFF作为码点值。
- 前导代理和后尾代理是什么?
在utf16编码中,在使用4字节进行编码的时候,第一个码元称为前导代理,后面的码元称为后尾代理
- 为什么是个前导代理的前6位必须是
110110,后尾代理的前6位必须是110111呢?UTF16在读取一段字节流的时候,还原成unicode码点的时候,怎么知道是需要读取两个字节进行解析呢, 还是需要读取4个字节进行解析呢?
这肯定就需要一个特殊的码点,当解析的字节是这个码点的时候就知道 我要读取后面的剩余字节去解析出一个完整的码点。UTF16就是利用在Unicode规范中规定,BMP平面的
U+D800到U+DFFF之间的码位区段是永久保留不映射到Unicode字符的。D8转换成二进制就是11011000.DC转换成二机制为110111,任然是在U+D800到U+DFFF的范围内的。于是解码读取 字节流的时候就可以根据这两个标志位(0xD8和0xDC)确定这个字节是一个前导代理还是一个后尾代理, 然后解析出一个完整的unicode码点。
五. UTF-32编码
UTF32是定长编码类型,采用4个字节表示一个unicode码点。而unicode字符所有的码点最大的只要3个字节 便可以完全表示,所以完全不用有什么编解码的操作,使用4字节的数据长度表示最大只有3字节长度的数据。 缺点就是耗费空间了,对于大多数字符都是在BMP平面的来说,大小就会膨胀接近4倍。
六. java与unicode
我们都知道java使用UTF16做内部编码,就是jdk在内存中存储一个字符的时候,其字节流是怎么存储一个 Unicode码点的?
6.1 java为什么使用UTF16作为内部字符串编码?
为什么java内码用UTF16而不使用UTF8呢?UTF8内存占用肯定会比UTF16小,那为什么不用呢? 这个问题要结合字符串性能,还有java发展的历史来说。
- 首先要说的就是UTF8和UTF32对比的缺点,UTF8需要进行编解码,涉及到CPU计算,有性能消耗。而UTF32 可以直接表示所有的unicode码点,无序任何转码操作,所见即所得,浪费了空间提升了性能
- 在java最开始定规范的时候,unicode还处于1.0阶段,此时unicode码点值只有两个字节,并且认为2个 字节便足以表示所有的字符了。于是java在一开始的时候就以空间换时间的思路,不使用UTF8编码,因为utf8的 编解码需要损耗性能,直接使用2个字节的定长数据结构表示所有的Unicode字符。所以一开始java规范里就没想 过要用什么字符编码,直接一个char表示所有的unicode字符。但是随着unicode2.0规范的颁布,以及3.0的第 一批增补字符的添加,原来的2字节的char已经不能表示所有的unicode字符了。为了兼容以前char,同时又能正 确表示出增补字符,java只能通过UTF16的方式进行编码字符串了,使用两个char4个字节来表示后面Unicode新 增的增补平面的字符。
如何将一个16进制的码点值转换成对应的字符? 假如知道一个码点值为:0x204C5,将其转换成对应的字符 思路:
- 将码点值转换成整数,由于Unicode码点值最大为0x10FFFF,所以一个int足够了
- 判断这个字符需要一个char表示还是两个char表示
- 两个char表示的话需要进行编码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public static String convertCodePoint2String(String hex){
if(!(hex.startsWith("0x") || hex.startsWith("0X"))){
hex = "0x"+hex;
}
int codePoint = Integer.decode(hex);
StringBuilder sb = new StringBuilder();
if(codePoint <= Character.MAX_VALUE){
char r = (char)codePoint;
sb.append(r);
}else if(codePoint > Character.MAX_VALUE && codePoint < 0x10FFFF){
char a = (char) ('\uD800'+ ((codePoint-0x10000) >>> 10));//等同于Character.highSurrogate(codePoint);
char b = (char) ((codePoint & '\u03FF') + '\uDC00');//等同于Character.lowSurrogate(codePoint);
sb.append(a).append(b);
}else{
throw new IllegalArgumentException("out of range : Unicode code point");
}
return sb.toString();
}
6.2 Hessian的字符串编解码
java中的一个每个char都是经过了UTF-16进行编码的了,hessian在编码的过程中又会将每一个char进行UTF-8 编解码。并且hessian的utf8编解码方式比传统的String.getBytes(“ss”)新能更好. 下面截取一段hessian 的字符串序列化代码,看看hessian中的UTF8编码具体实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
public void printString(String v, int strOffset, int length)
throws IOException
{
int offset = _offset;
byte []buffer = _buffer;
for (int i = 0; i < length; i++) {
if (SIZE <= offset + 16) {
_offset = offset;
flushBuffer();
offset = _offset;
}
char ch = v.charAt(i + strOffset); //拿出字符串中的每一个char
//对每一个char做UTF8编码
if (ch < 0x80)//根据UTF8编码规范,单字节编码,兼容ASCII码
buffer[offset++] = (byte) (ch);
else if (ch < 0x800) {//根据UTF8编码规范,双字节编码
//根据UTF8编码规范,取char的前5位,放第一个字节。0x1f = 00011111
buffer[offset++] = (byte) (0xc0 + ((ch >> 6) & 0x1f));
//根据UTF9编码规范,取char的后6位,放第二个字节。0x3f = 00111111
buffer[offset++] = (byte) (0x80 + (ch & 0x3f));
}
else {//根据UTF8编码规范,3字节编码
buffer[offset++] = (byte) (0xe0 + ((ch >> 12) & 0xf));
buffer[offset++] = (byte) (0x80 + ((ch >> 6) & 0x3f));
buffer[offset++] = (byte) (0x80 + (ch & 0x3f));
}
}
_offset = offset;
}